-
시작하는 이들을 위한 mongoDB Aggregation 가이드whatIRead 2022. 11. 25. 16:56
예전에 몽고디비 사용할 때 읽으면서 정리해뒀던건데, 노션에서 작성해두고 그냥 뒀던것을 이제 올린다.
이럴거면 그냥 노션을 쓸까..
https://studio3t.com/knowledge-base/articles/mongodb-aggregation-framework/
MongoDB Aggregation: tutorial with examples and exercises | Studio 3T
Master the MongoDB aggregation pipeline. Follow along with query examples using the most important aggregation stages, and test your skills!
studio3t.com
mongoDB를 시작할 때, 당신은 넓은 범위의 쿼리를 위해 find()명령어를 사용할 것이다. 하지만, 당신의 쿼리가 점점 진화할 수록, 당신은 Aggregation에 대해 알아야할 것이다.
이 글에서, 몽고DB의 aggregation query를 작성하는 주요 원칙과 인덱스를 활용한 최적화 방법을 설명합니다.
Aggregation 이란?
Aggregation은 여러 단계를 거치는 방법을 통해 collection 내의 많은양의 문서들을 처리하는 방법입니다. stage들은 파이프라인을 생성합니다. 파이프라인 내에서 filter, sort, group, reshape, 문서 수정을 합니다.
Aggregation의 가장 전형적인 유형중 하나는 문서의 그룹을 집계값을 계산하는 것입니다. 이는 SQL의 기본적인 집계인 GROUP BY절과 COUNT, SUM, AVG 기능과 비슷합니다. MongoDB Aggregation은 더 나아가 join과 같은 수행을 할 수 있고, 문서의 형태를 변경하거나, 새롭게 만들거나, 기존 컬렉션을 업데이트 하는 등의 기능을 수행할 수 있습니다.
mongoDB에서 집계 데이터를 얻기위한 방법이 있지만, aggregation framework는 대부분의 작업에 권장되는 방식입니다.
find() 쿼리에 붙어 빠르게 사용할 수 있는 단일 목적의 estimateDocumentCount(), count(), distinct()가 있지만, 범위가 제한됩니다.
map-reduce 프레임워크는 aggregation framework의 처리기이고, 사용하기 더 어렵습니다. mongoDB는 해당 기능을 더이상 사용하지 않습니다.
mongoDB aggregation 파이프라인은 어떻게 동작하나요
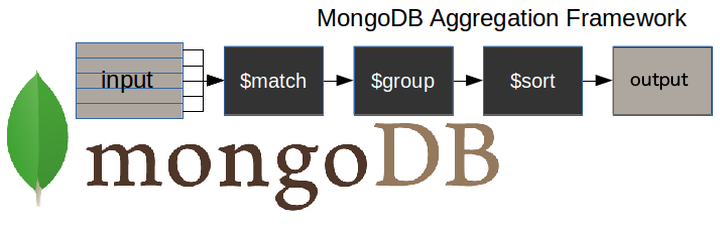
전형적인 mongoDB aggregation 파이프라인을 나타낸 그림입니다. - $match stage - 필요한 문서를 필터합니다.
- $group stage - 집계 작업을 합니다.
- $sort stage - (오름차순, 내림차순) 으로 필요로하는 결과 문서를 정렬합니다.
파이프라인의 입력은 단일 콜렉션일 수 있으며, 아래의 파이프라인에서 다른 컬렉션이 병합될 수 있습니다. 파이프라인은 목표가 달성될 때 까지 데이터에 대해 연속적인 변환을 수행합니다.
이렇게하면 복잡한 쿼리를 더 쉬운 단계로 나눌 수 있으며, 각 단계에서 데이터에 대해 서로 다른 작업을 완료합니다. 따라서 쿼리 파이프라인의 끝에, 우리가 원하는것을 얻을 수 있습니다.
이 접근방식을 사용하면 입력과 출력 모두 검사하여 쿼리가 모든 단계에서 제대로 작동하는지 확인할 수 있습니다. 각 단계의 출력은 다음단계의 입력이됩니다.
쿼리에 사용되는 단계의 수나 결합 방법에는 제한이 없습니다.
MongoDB 집계 파이프라인 구문
aggregation query 빌드를 어떻게하는가에 대한 예시입니다.
db.collectionName.aggregate(pipeline, options)
- collectionName - 콜렉션의 이름
- pipeline - aggregation stage를 포함한 array
- options - aggregation을 위한 선택적인 파라미터
pipeline = [ { $match : { … } }, { $group : { … } }, { $sort : { … } } ]MongoDB aggregation stage의 한계
aggregation은 메모리에서 작업합니다. 각각의 스테이지는 100MB의 램을 사용합니다. 이 한계를 넘는 작업을 한다면 에러를 마주치게됩니다.
이를 피할 수 없는 경우, 디스크에서 페이징하도록 선택할 수 있지만 메모리보다 디스크에서 작업하는것이 더 느리기 때문에 시간상의 단점이 있습니다. 디스크에서 읽는 방식을 선택하기 위해 alloDiskUser 옵션을 사용합니다.
db.collectionName.aggregate(pipeline, { allowDiskUse : true })이 옵션은 샤드 서비스에서 항상 사용 가능한것이 아님을 기억하세요. 예를들어 아틀라스 M0, M2, M5 클러스터는 해당 옵션을 사용할 수 없습니다.
다른 콜렉션에서 $out 을 경유해 저장되거나 cursor, aggregation query 에 의해 반환되는 문서들은 16MB의 한계를 가집니다. 즉, mongoDB의 문서크기보다 클 수 없습니다.
만약 한계치에 다다를 것 같다면, aggregation query 출력 문서가 아닌 커서로 표시되도록 지정해야합니다.
'whatIRead' 카테고리의 다른 글
비전공자를 위한 이해할 수 있는 it 지식 (0) 2022.05.06 CODE (0) 2022.05.03 [독서] 인사이드 자바스크립트 (0) 2021.08.23 왜 몽고디비를 쓰는가? (0) 2021.06.28 package-lock.json (0) 2021.06.25